Coming Soon
OVTAS: Zero-Shot Action Segmentation
Exploring Vision-Language Models for Open-Vocabulary Zero-Shot Action Segmentation.
Selected peer-reviewed papers in HCI, AR, and Computer Vision.
Google Scholar Profile →
Exploring Vision-Language Models for Open-Vocabulary Zero-Shot Action Segmentation.
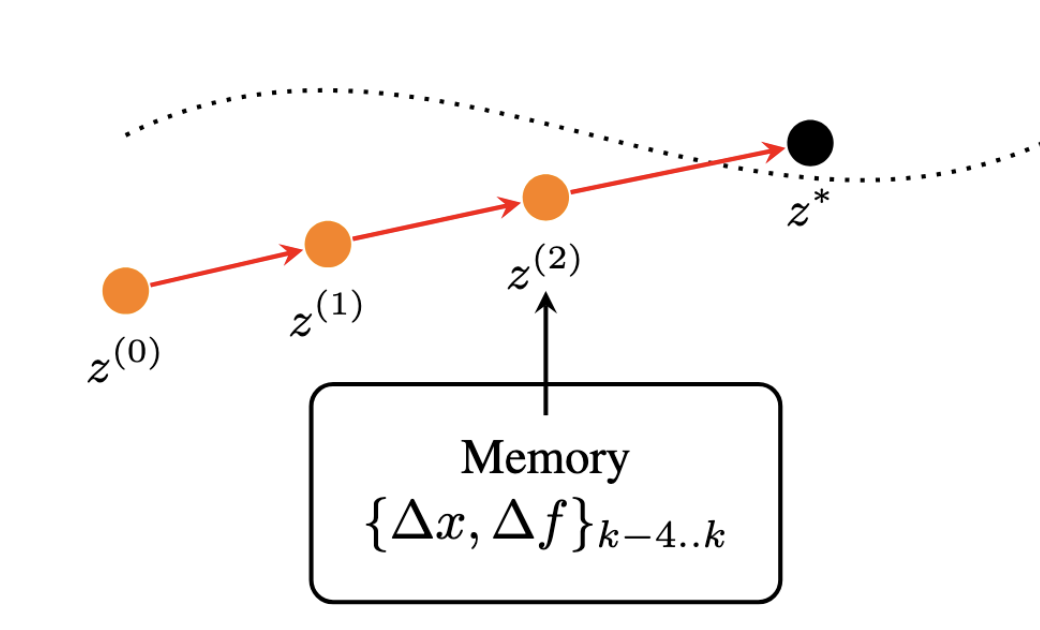
Gradient-Free Image Inversion via Quasi-Newton Diffusion Solvers.
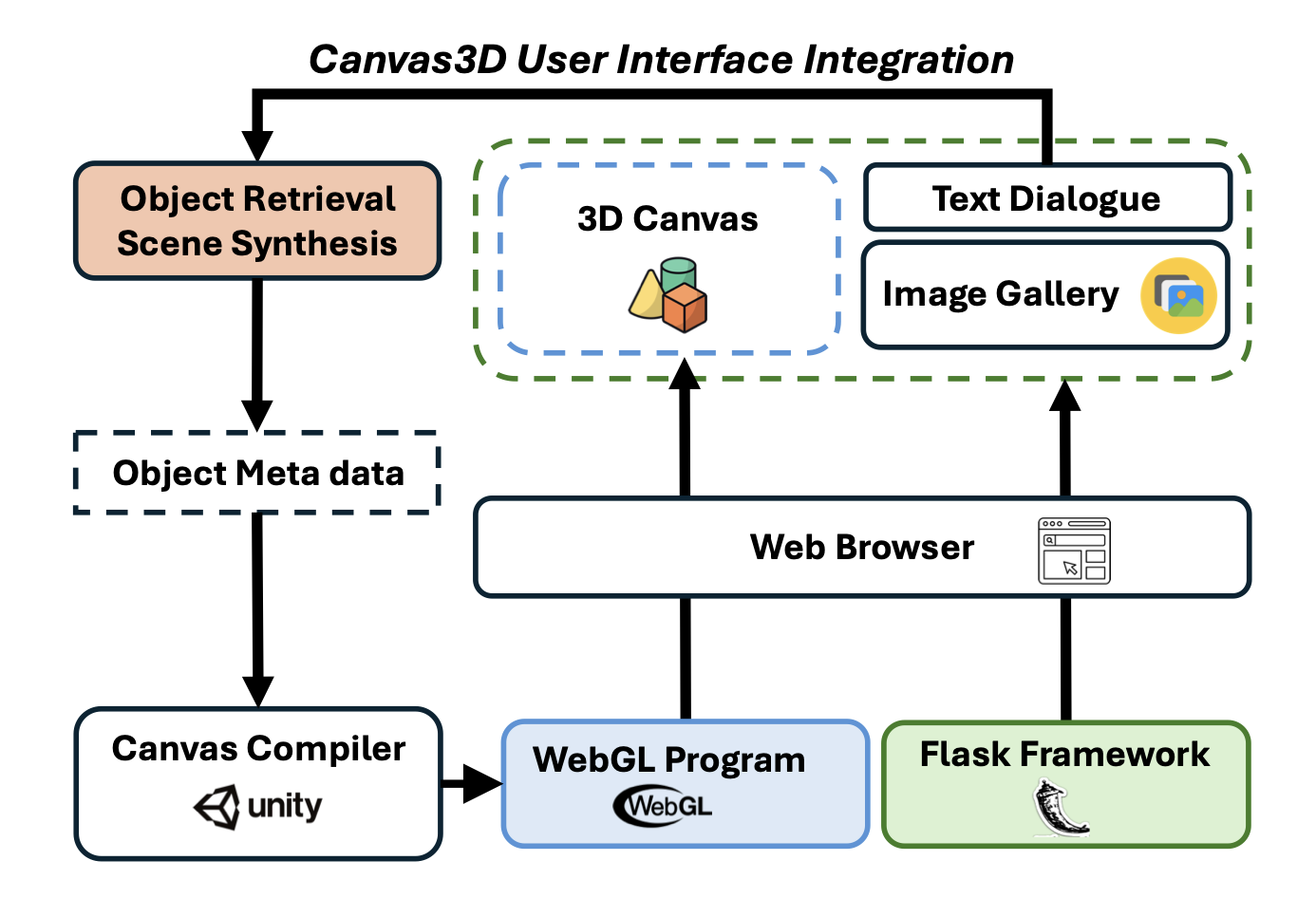
Empowering Precise Spatial Control for Image Generation with Constraints from a 3D Virtual Canvas.
Leveraging Narrated Instructional Videos to Create Augmented Reality Tutorials for Procedural Tasks.
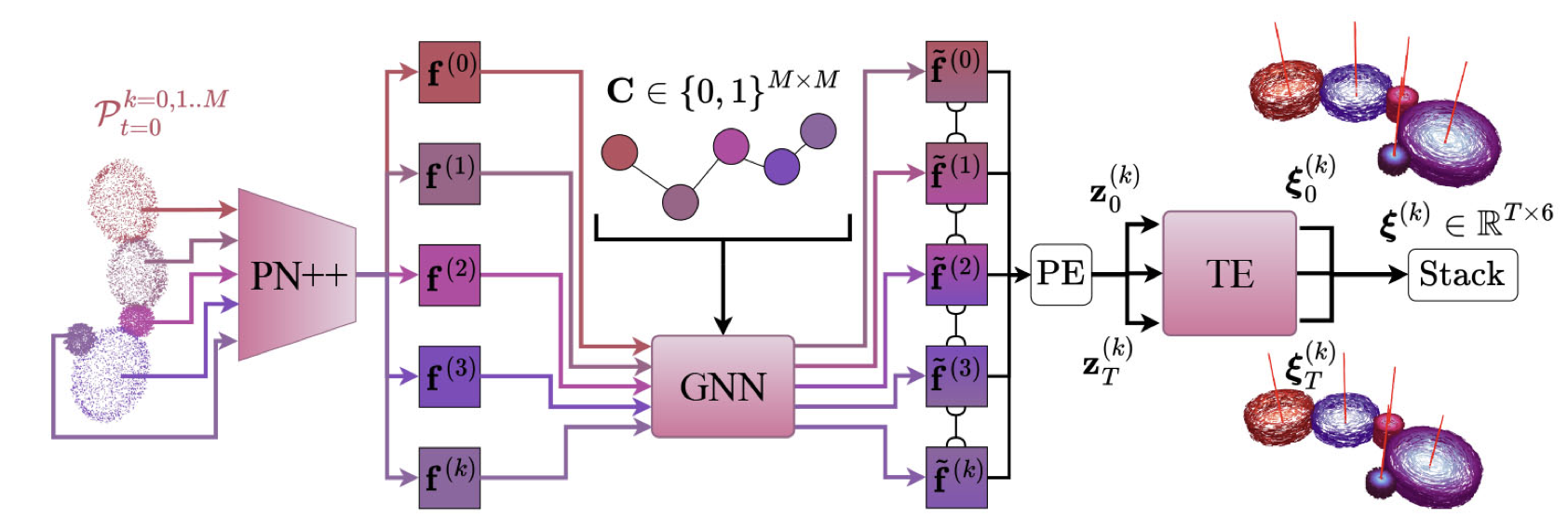
Dependency-Aware Deep Learning Framework for Articulated Assembly Motion Prediction.
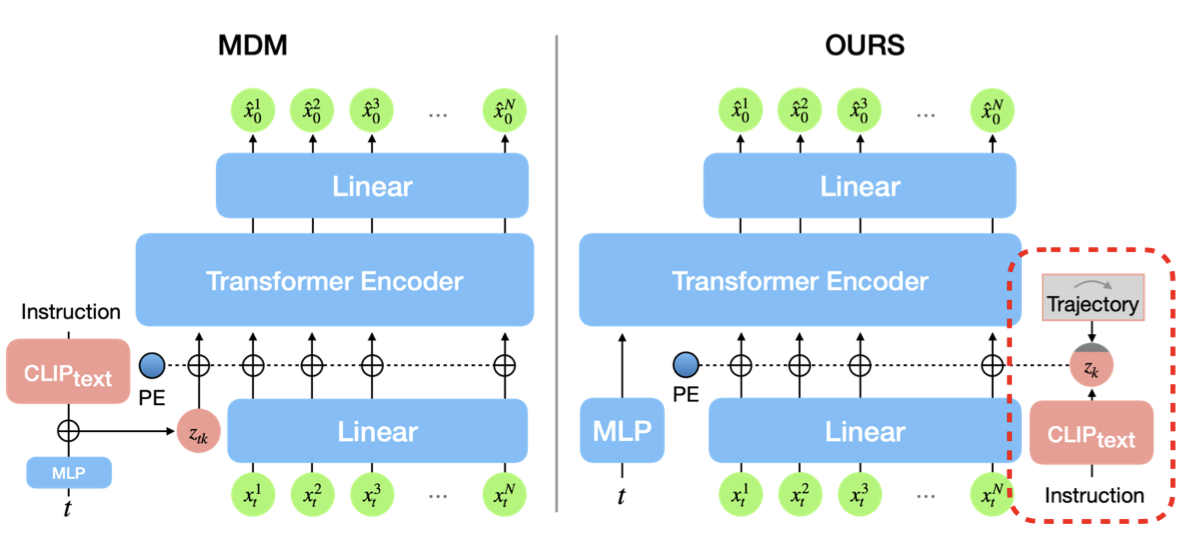
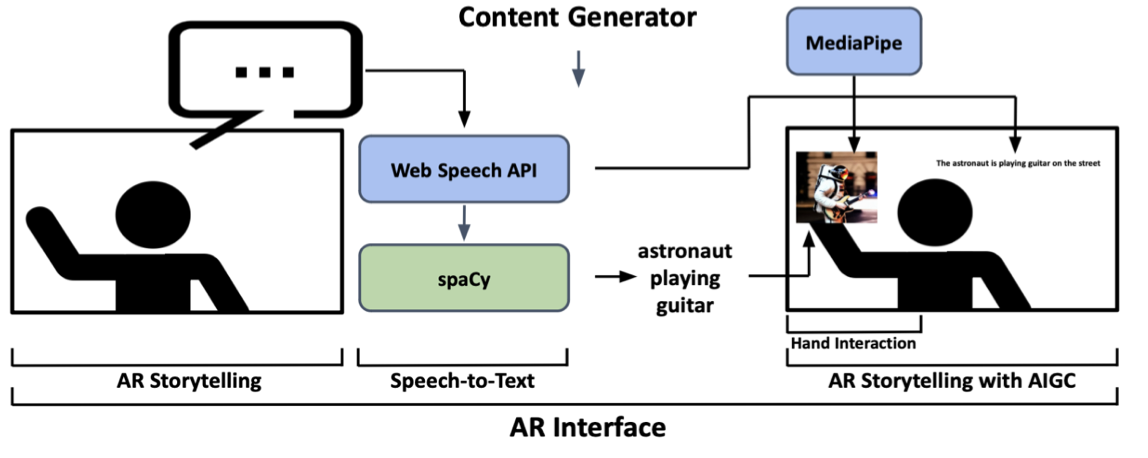
Towards Authoring Context-aware Augmented Reality Instruction through Generative AI.
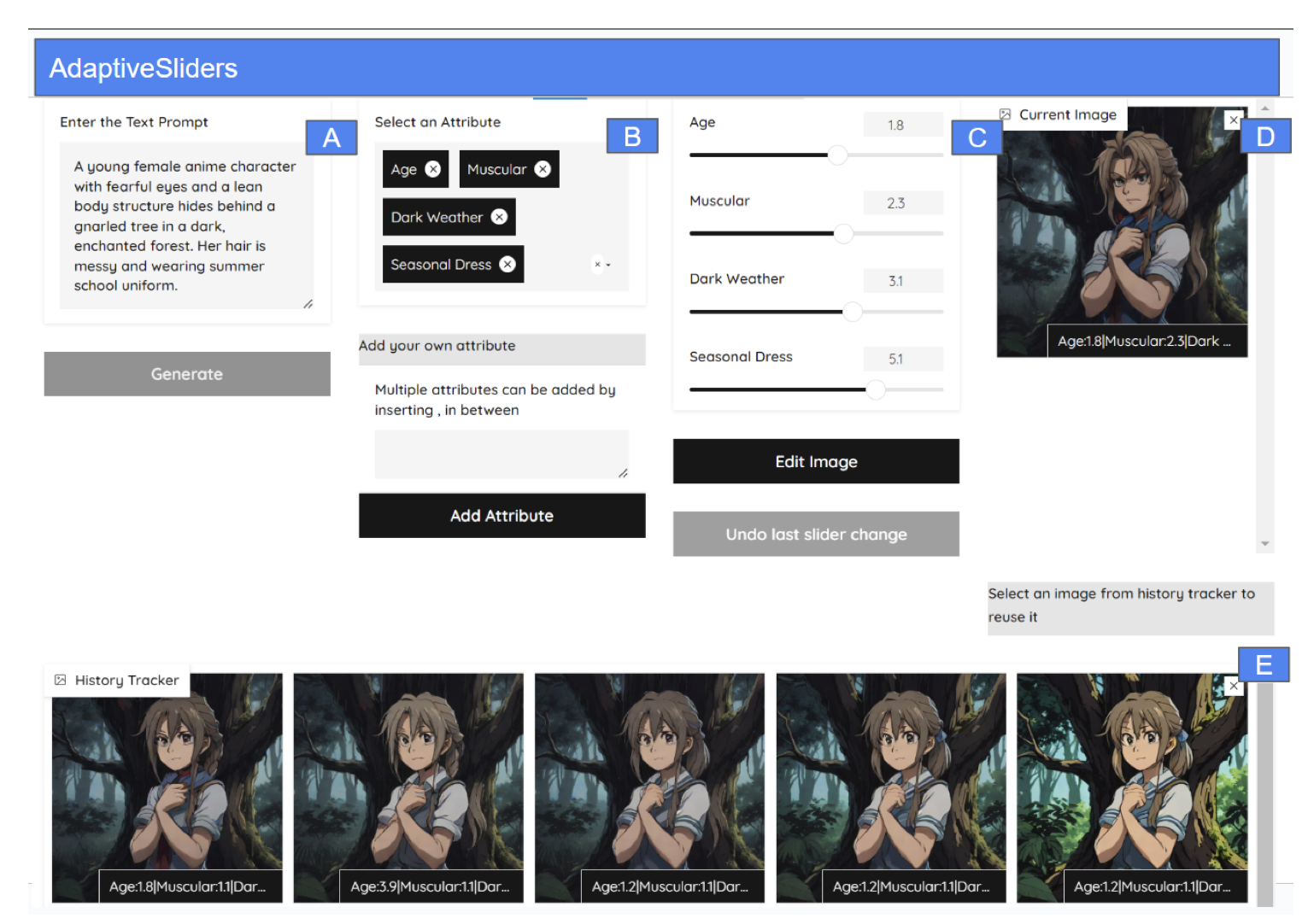
User-aligned Semantic Slider-based Editing of Text-to-Image Model Output.
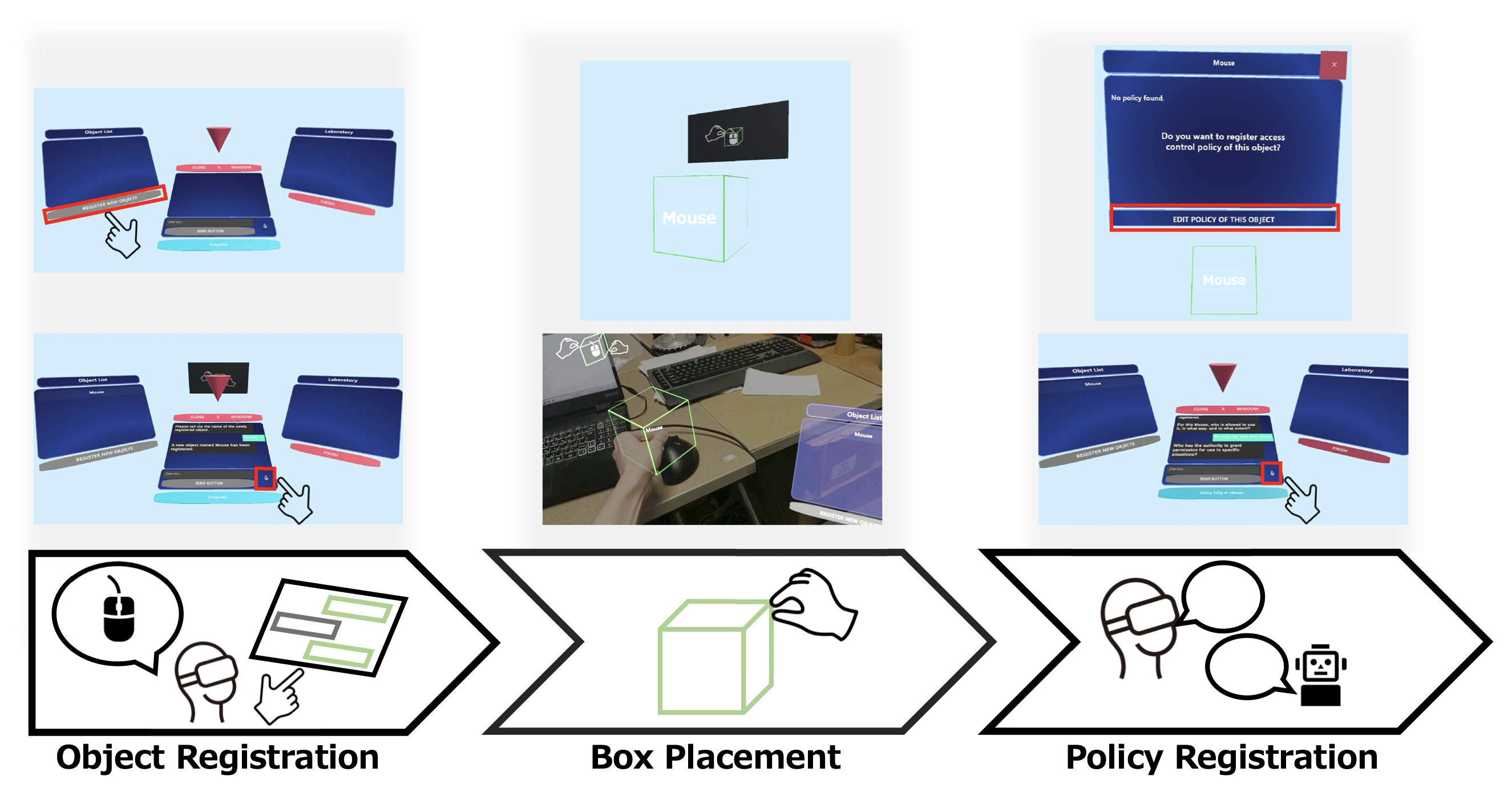
Natural Language Access Control Policies for XR-Enhanced Everyday Objects.
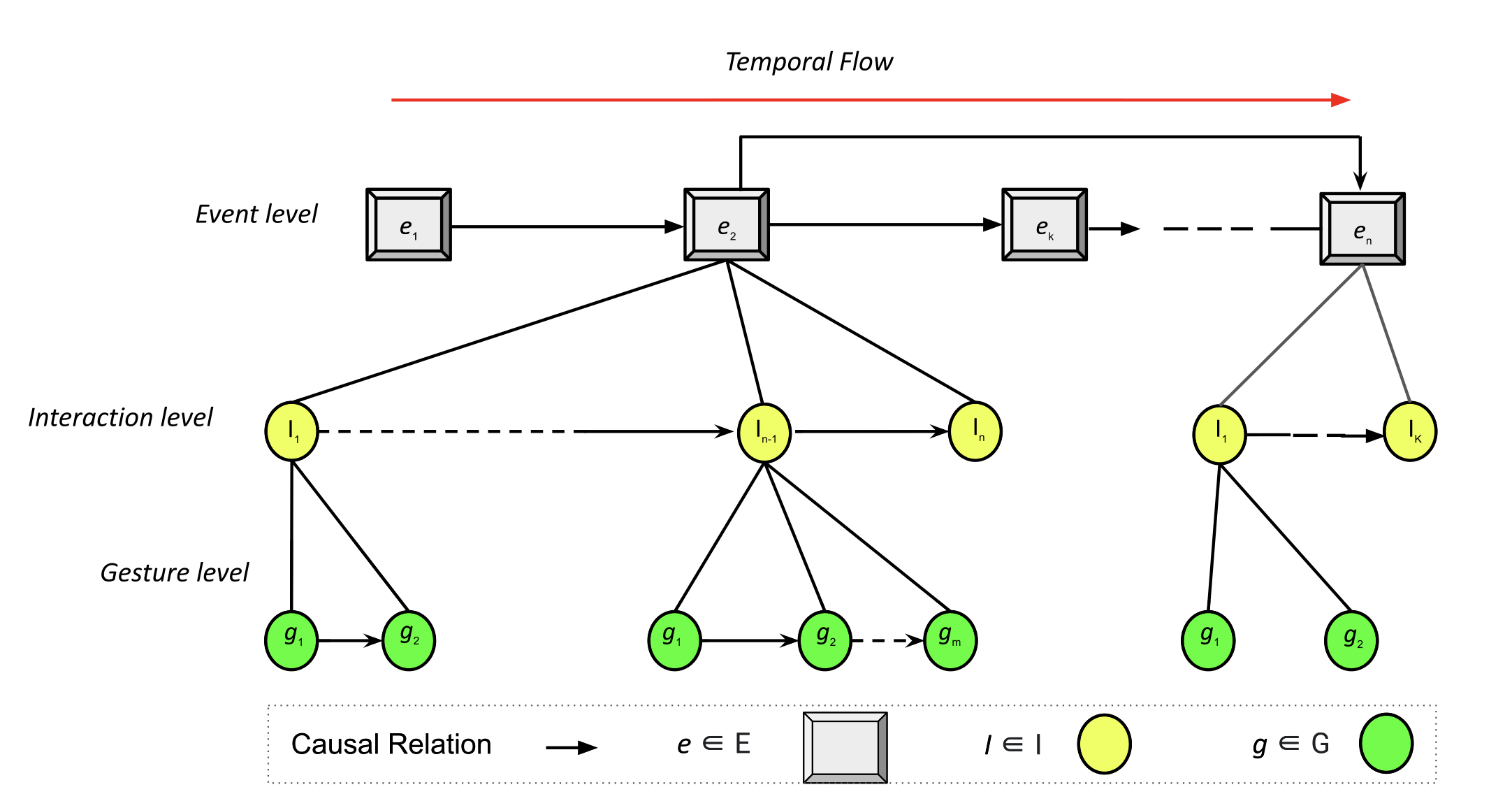
Visualizing Causality in Mixed Reality for Manual Task Learning: A Study.
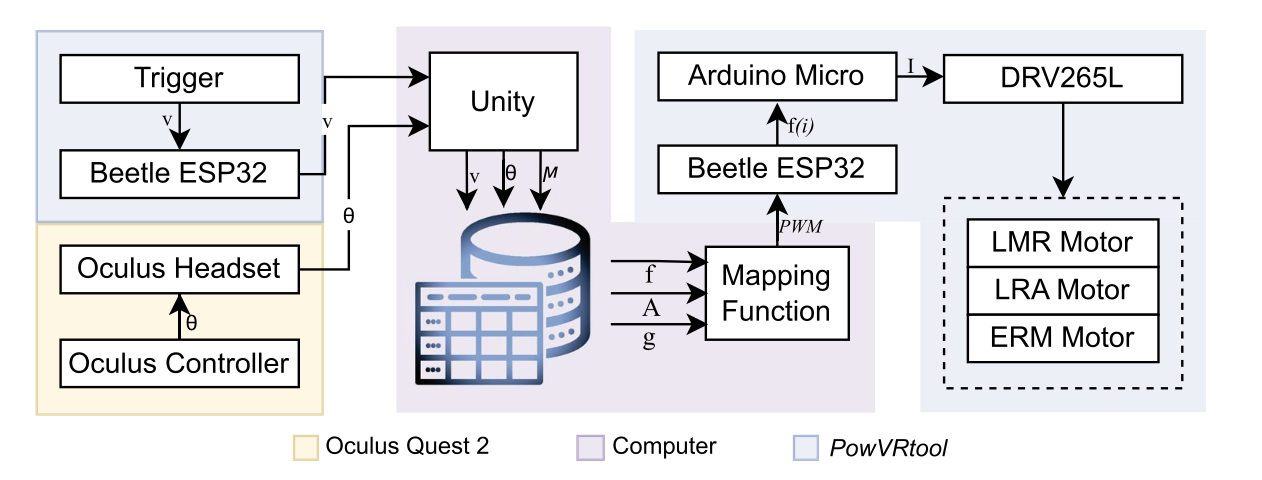
A handheld haptic device for realistic power tool feedback in VR-based manufacturing training.
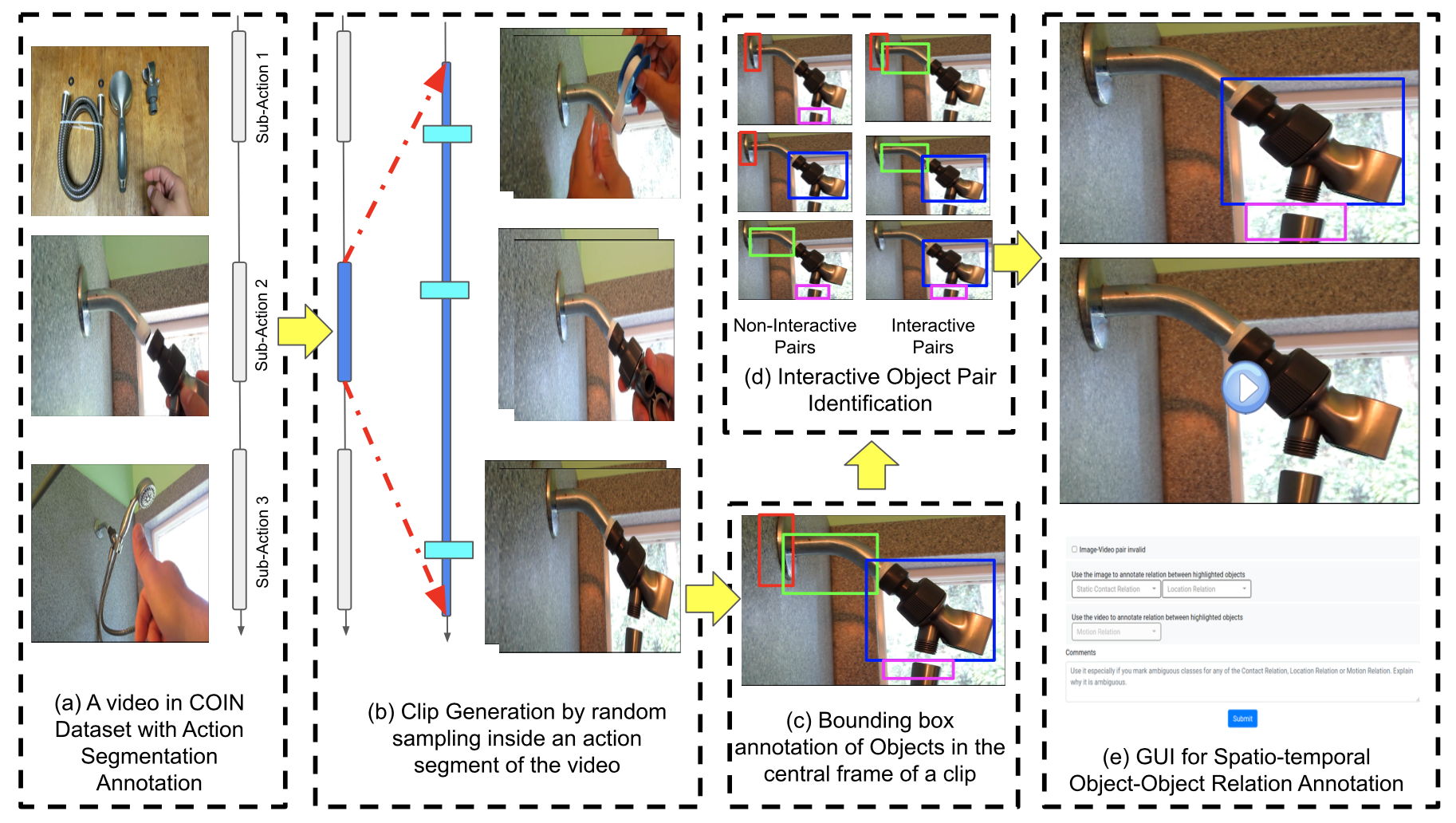
A Dataset of Object-Object Interactions for Richer Dynamic Scene Representations.
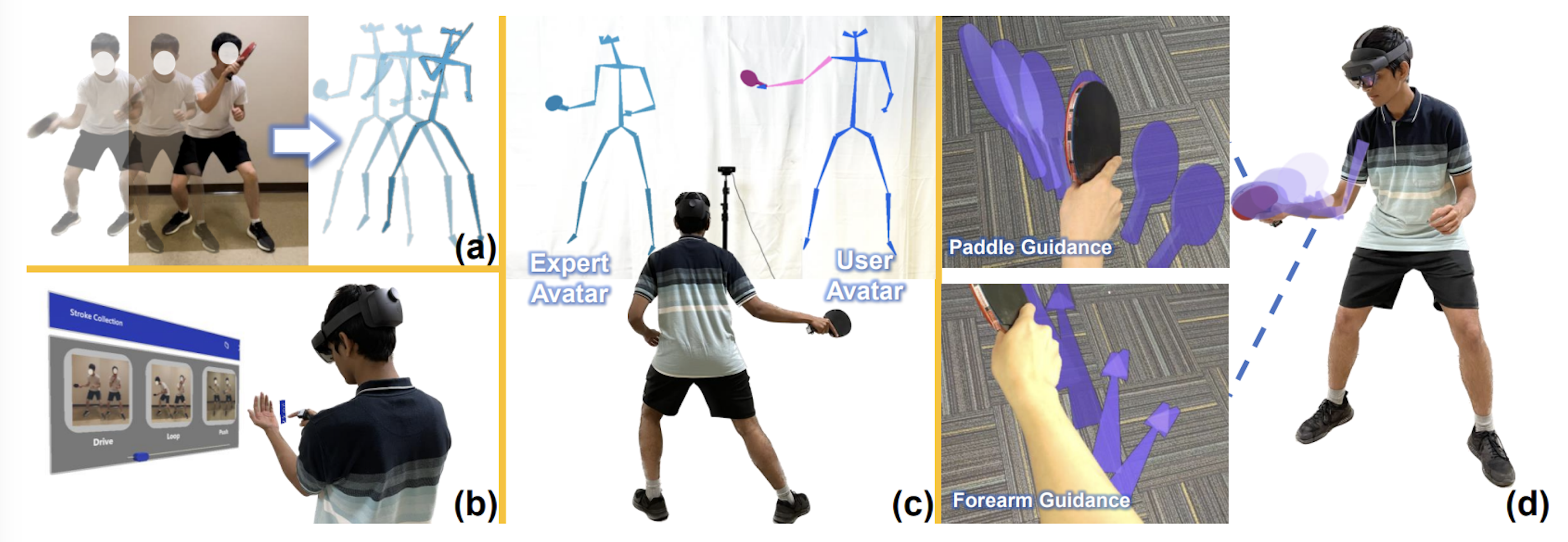
Stroke training with embodied and detached visualization in augmented reality.

An extended reality workflow for automating data annotation to support computer vision.
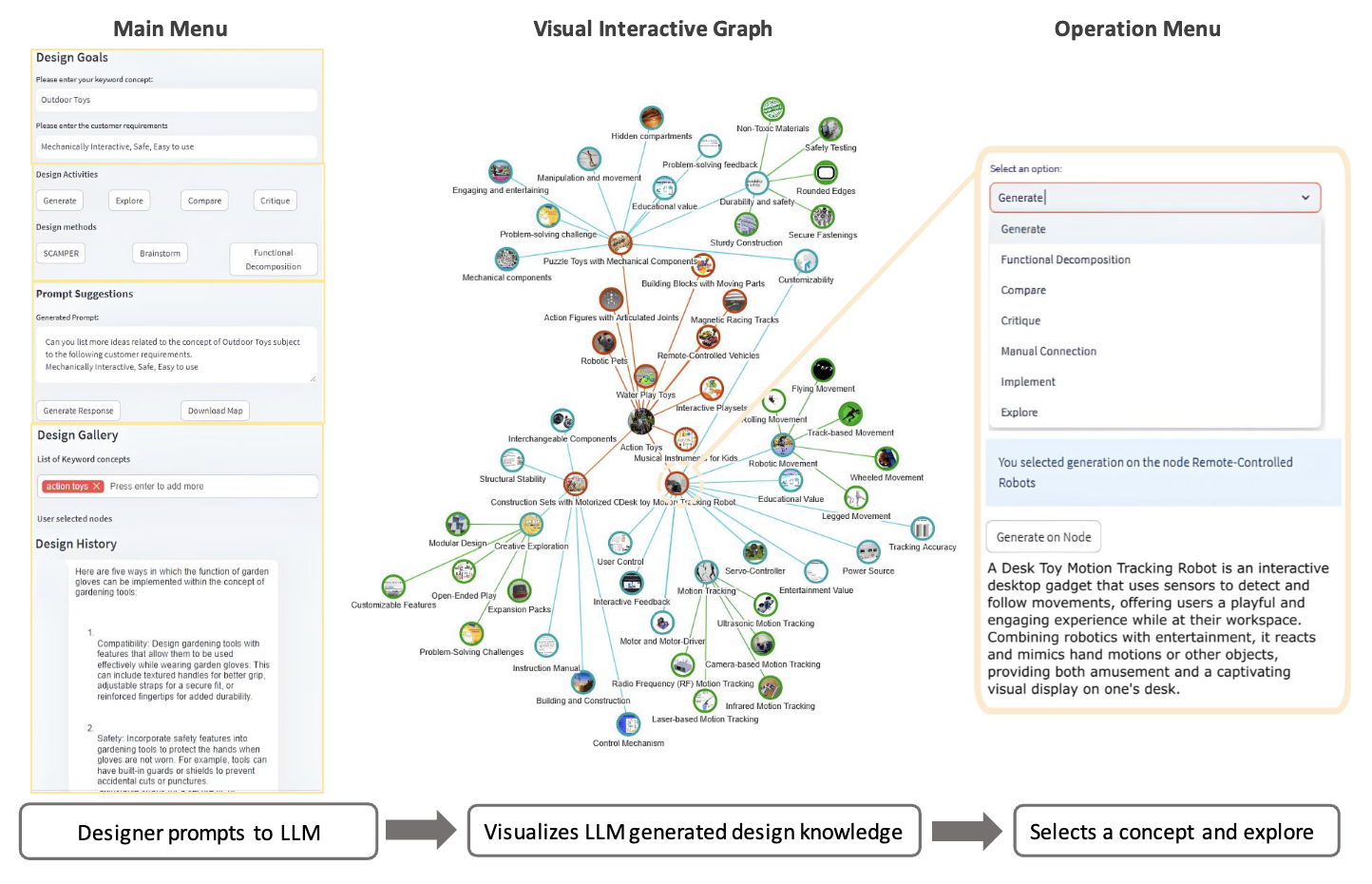

Ubiquitous Tangible Object Utilization through Consistent Hand-object interaction in AR.
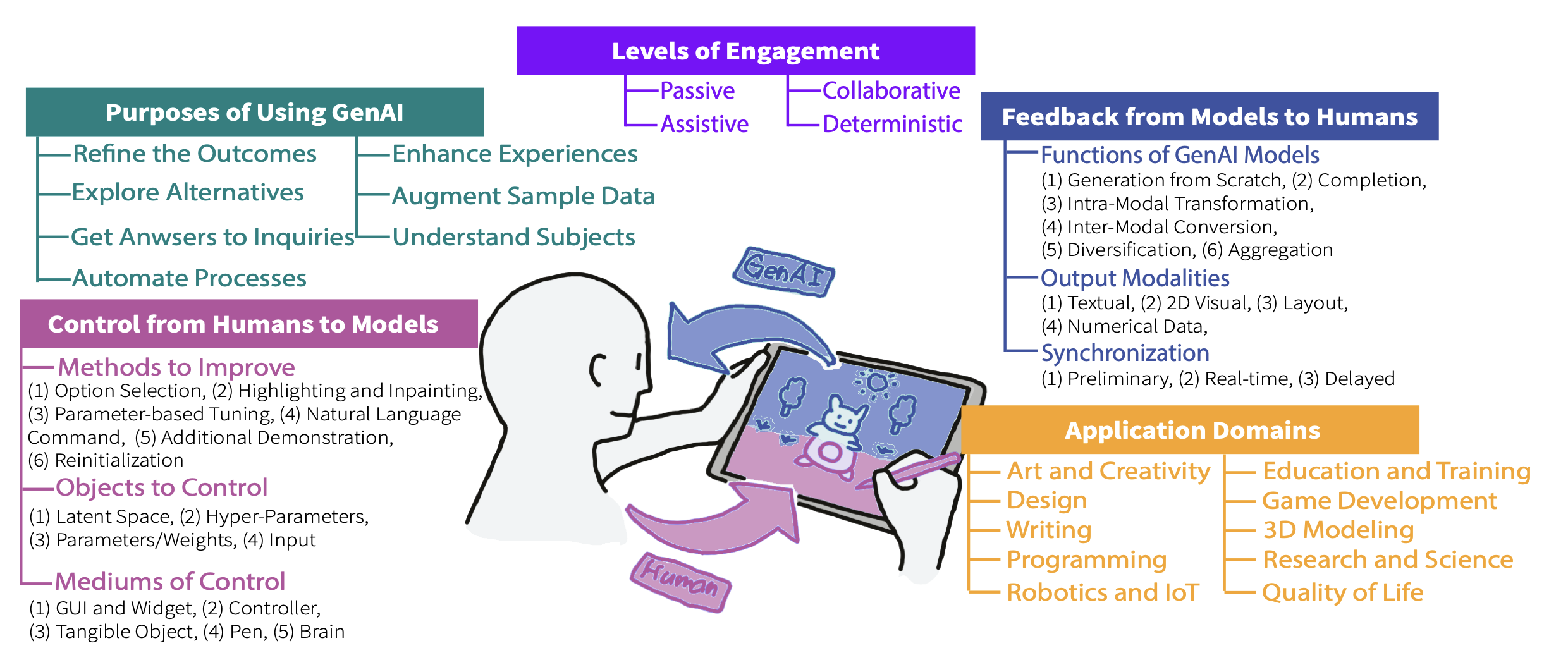

Understanding generative AI in art: an interview study with artists on G-AI from an HCI perspective.