
OVTAS: Zero-Shot Action Segmentation
Exploring Vision-Language Models for Open-Vocabulary Zero-Shot Action Segmentation. We demonstrate how VLMs can decompose complex long-form videos into meaningful steps without prior training examples.
Exploring Vision-Language Models for Open-Vocabulary Zero-Shot Action Segmentation. We demonstrate how VLMs can decompose complex long-form videos into meaningful steps without prior training examples.
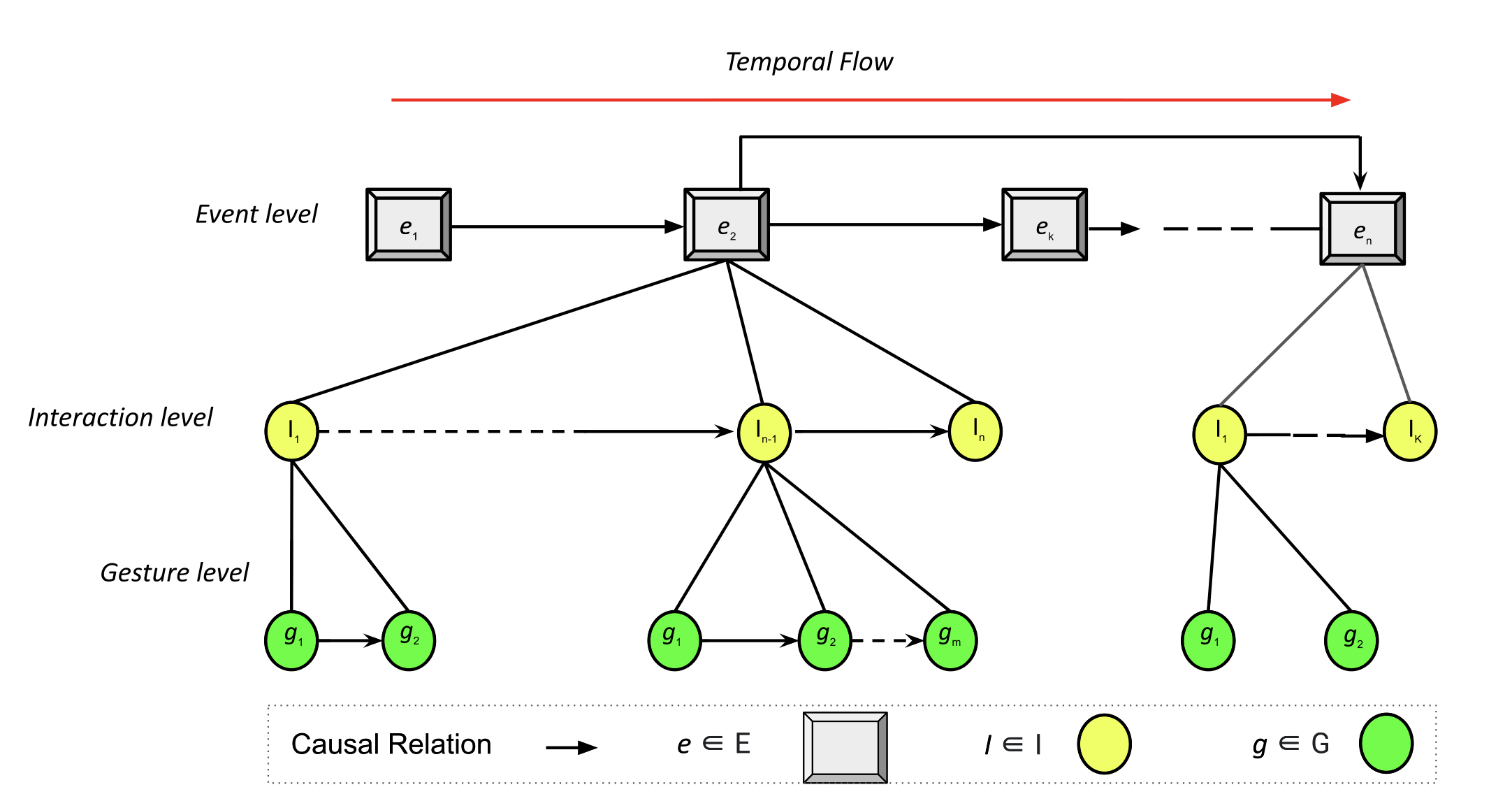
Visualizing Causality in Mixed Reality for Manual Task Learning. A framework for identifying and visualizing the "why" behind physical actions, helping users understand task dependencies intuitively.
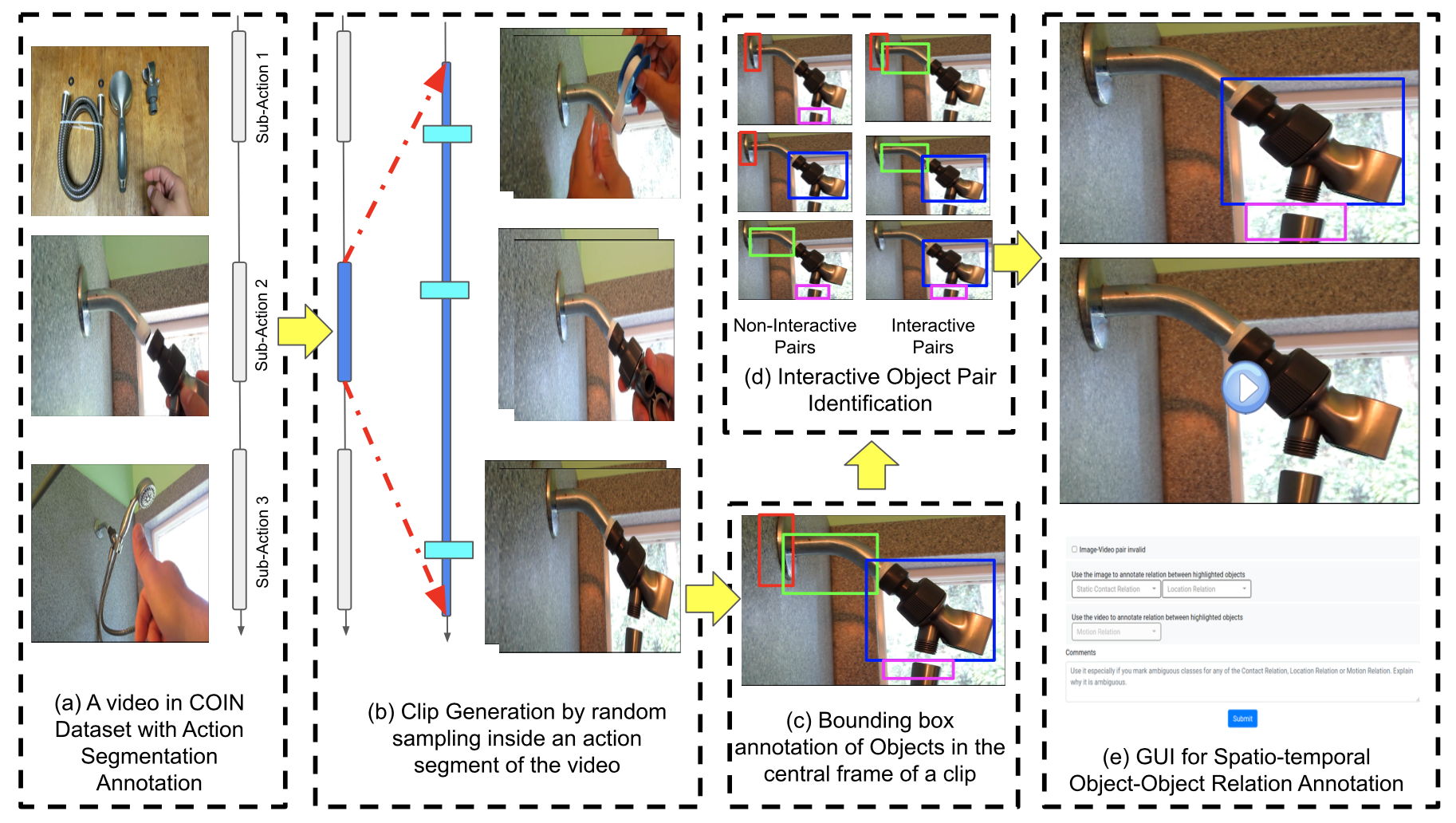
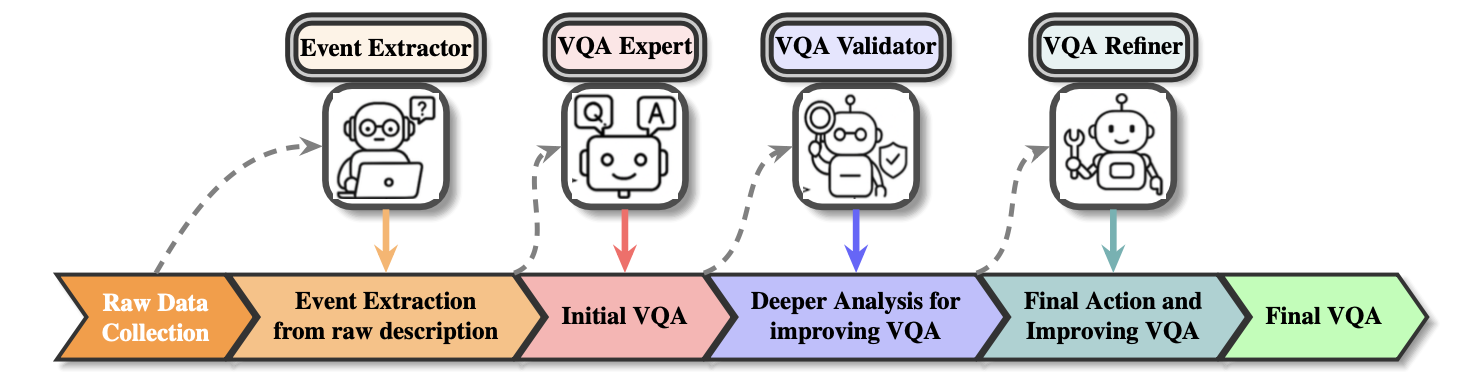
Narrative Aligned Long Form Video Question Answering. A method for grounding QA in the narrative structure of movies and long videos, improving reasoning over long temporal horizons.

An extended reality workflow for automating data annotation. We allow researchers to collect and auto-label high-fidelity training data for computer vision by simply performing the task in XR.